Researches研究内容
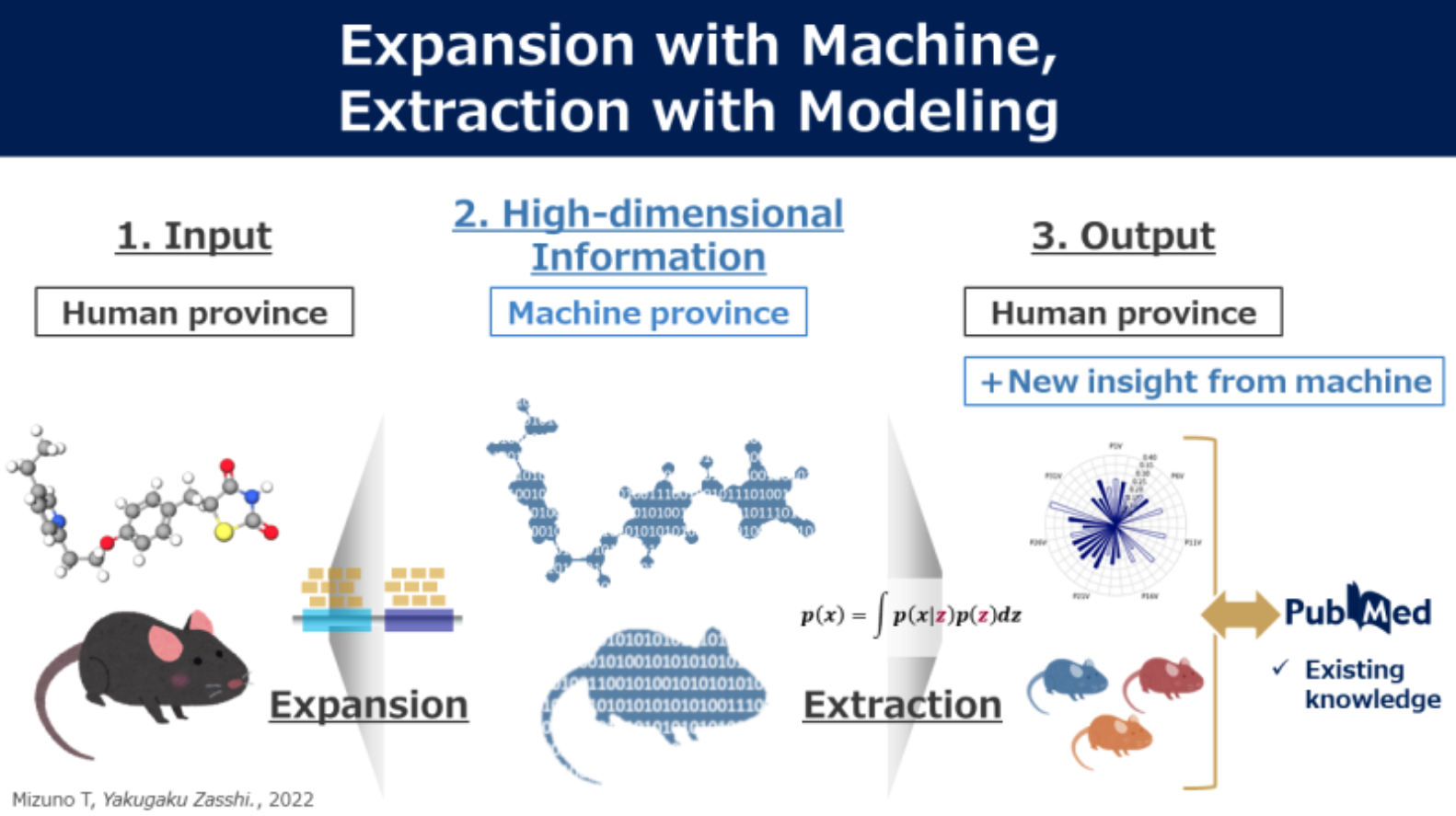
我々ヒトが化合物の特性を思い浮かべるとき, 例えばある化合物は官能基Aを持ち, 毒性Tを示す分子量がMの化合物であるといった具合に認識する。このように我々が扱える次元はたかだか数次元であるものの, 計算機を用いることでより高次元の情報を扱うことができる。そのため, 恣意性なく網羅的に解析対象を高次元の情報体として数値化することは, 計算機を用いて我々の解析対象に対する認識を拡張する上で必須な操作である。同時に, このようにして拡張された高次元の情報を再び我々が認識可能な次元へと出力するモデリングも欠かせない。逆説的に, 数値化とモデリングにより, 我々は自身の認識を超えた情報量を扱い, 解析対象の新たな側面を見出すことを可能とする。我々のグループは上述の「計算機による認識の拡張とモデリングによる本質的な情報の抽出」を信条に, 化合物の理解と活用について研究を展開している。主たる技術は潜在変数モデルと表現学習である。
パータベーションを与えた培養細胞のオミクスデータを対照群のデータで適切に正規化することで, 網羅的かつ恣意性のない生体応答情報が得られる。ドラッグリポジショニングの成功等を鑑みれば, 化合物の作用は複合的であり, 開発者も認識していない側面が多く存在すると考えられる。複合的作用を理解するため, 我々はオミクスデータに由来する生体応答情報を因子分析に供して化合物の作用を分解する戦略を提案し, 医薬品の潜在的な毒性の検出や天然物の作用理解等の成果を挙げている。
病理画像は疾患の確定診断にも用いられるように, 個体の状態を記述する豊富な情報量を持つデータである。安全性評価で取得される毒性病理画像は, 化合物への個体の作用を反映したデータとみなせる。しかし一般に病理画像からの情報抽出はハンドメイドな病理所見に基づいて行われているため, 頑健で解釈性は高いものの, 病理画像が持つ豊富な情報量を記述できてはいない。我々は, 深層学習により特徴量を抽出する表現学習を用いて病理画像を数値化することで, 化合物の個体での作用を数値化し, その理解と応用に取り組んでいる。
SMILESなどの化合物構造を表現する文字列を対象に, 言語モデルを用いて様々な化合物関連のタスクに取り組む方法論は化学言語モデルと呼ばれる。一方, どのように化学言語モデルが多様な化合物の構造を学習・認識しているかについてはほとんど知見が存在しない。我々はモデルの学習進捗に着目し, 言語モデルとしての性能と化合物構造との関係性の理解に取り組んでいる。また化学言語モデルを精緻化することで様々な乱数からの構造生成を実現しており, virtual screeningをベースとしたドラッグデザインにも取り組んでいる。